
If you’ve worked on a high-scale SaaS platform, you’ve probably heard the promise: “Event-driven architecture (EDA) will solve our scalability problems.”
In theory, it should. In practice, I’ve seen dozens of SaaS platforms hit a hard wall at around 40,000–60,000 concurrent users. They didn’t crash because the database failed, and they didn’t go down because the infrastructure ran out of capacity. They failed because the system quietly fell into what is known as a platform event trap.
In 2026, this is no longer just a technical flaw. It is a critical business risk. When event pipelines stall or spiral out of control due to autonomous AI agents, enterprise SLAs break, API costs explode, and Net Dollar Retention (NDR) takes a direct hit. What starts as an architectural shortcut often ends as churn, SLA credit paybacks, and loss of trust.

This guide explains exactly what the platform event trap is, why Agentic AI has made it the #1 threat to SaaS reliability, and how to escape it without rewriting your entire platform.
1. Defining the Trap: Legacy Signals vs. Modern Anti-Patterns
A Platform Event Trap is a critical architectural failure where an event bus becomes tightly coupled, leading to infinite retry loops, “poison messages,” and cascading system latency. In 2026, preventing these traps is essential for maintaining SaaS scalability, protecting FinOps budgets, and ensuring high Net Dollar Retention (NDR).
Before we dive into the “why,” we have to clear up the confusion. If you search for “platform event trap,” legacy documentation will point you to hardware signals.

Historically, a Platform Event Trap (PET) referred to IPMI or SNMP signals emitted by physical server components when they overheated or failed (see Oracle ILOM docs). Those traps were rare, visible, and localized to a single machine.
In the modern cloud-native stack, the meaning has flipped. A SaaS Platform Event Trap is an architectural anti-pattern where the event bus—the very mechanism designed to decouple services—becomes a point of tight coupling and cascading failure.
| Feature | Legacy PET (Hardware) | Modern SaaS PET (Microservices) |
|---|---|---|
| Origin | Physical Server Sensors (IPMI/SNMP) | Logic-level Event Bus (Kafka/EventBridge) |
| Primary Risk | Component overheating or failure | Agentic Event Loops & System-wide Lockup |
| Resolution | Replace hardware / update firmware | Architectural Decoupling & Circuit Breaking |
| Business Impact | Single Node Downtime | Exponential Cloud Costs & SLA Breaches |
2. The Anatomy of a Failure: Why Traps Occur
Event-driven systems promise “fire and forget.” The trap happens when teams forget the second half of the equation: governance and failure boundaries.
The “Poison Message” and the Retry Storm
In a healthy system, a failed event is handled, quarantined (DLQ), or dropped. In a platform event trap, a malformed or unexpected event—often caused by an unannounced schema change—gets retried endlessly.
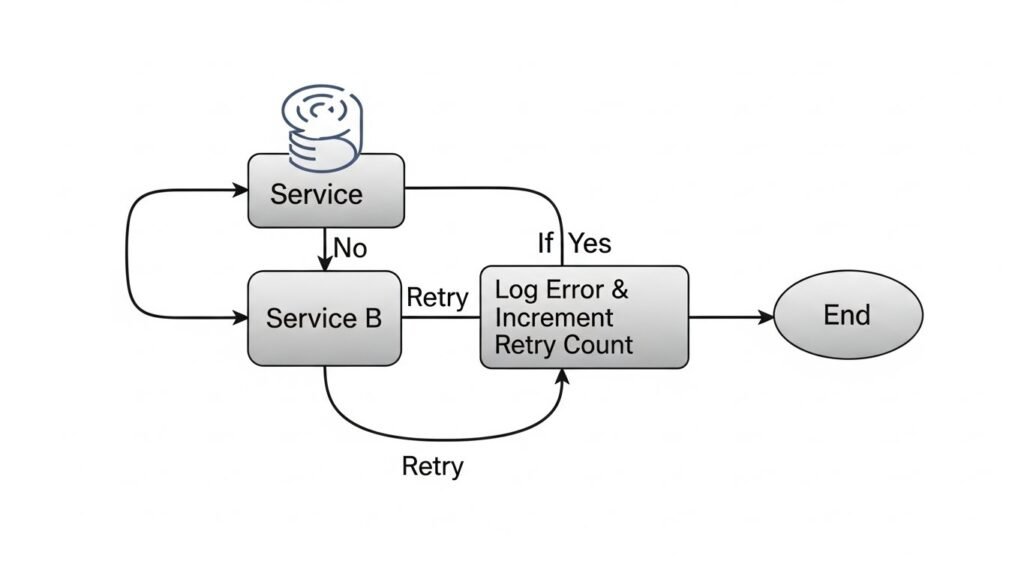
This creates a Death Spiral:
- Consumer Fails: Service B cannot process an event from Service A.
- Infinite Retry: The broker resends the event 10,000 times per minute.
- Resource Starvation: Service B’s CPU spikes processing failures, blocking valid traffic.
- Backpressure: Service A’s buffers fill up, causing it to crash.
The 2026 Threat: Agentic Event Loops (The “Self-DDoS”)
This is the new frontier. With the rise of Agentic AI (autonomous agents that can trigger actions), we are seeing “traps” that are not caused by bugs, but by valid logic running amok.
Imagine two AI agents:
- Agent A sends a “Task Updated” event.
- Agent B sees the update, performs an action, and triggers a “Task Complete” event.
- Agent A sees “Task Complete,” decides to archive the task, and triggers “Task Archived.”
- Agent B sees the archive action and tries to “Reopen” for verification.
Within minutes, you have created a self-reinforcing event loop. I have seen these loops burn through a month’s worth of OpenAI API credits and AWS Lambda invocations in less than 4 hours. This is effectively a self-inflicted DDoS attack.
⚠️ Critical Note: Unlike standard bugs, these loops often pass unit tests because each individual action is “correct.” The failure is in the interaction.
3. The Financial Trap: FinOps & Net Dollar Retention
Most engineers ignore this section. Most CTOs get fired over it.
A platform event trap is a direct threat to your Unit Economics.
- Cloud Bill Shock: In serverless environments (AWS Lambda / EventBridge), you pay per invocation. A trap that retries an event 50 times a second for an hour creates 180,000 excess billable events.
- SLA Credits: If your Enterprise plan guarantees 99.99% uptime, a “trap” that stalls processing for 20 minutes can trigger automatic penalty payouts.
- Net Dollar Retention (NDR): Reliability is the #1 driver of churn in 2026. If your system feels “sluggish” because of backend event lag, users churn.
4. Diagnosis: How Do I Know if My System Has a Trap?
You won’t always see a red alert. The most dangerous traps are subtle “grey failures.”
The “Missing Log” Phenomenon
One of the major platform event observability blind spots is the silent drop. High-performance brokers might drop events when buffers overflow without raising application-level errors. If your data is inconsistent (e.g., the user sees “Processing…” forever) but your logs look clean, you are likely in a trap.
Cascading Latency (The “Contagion”)

Platform event trap in microservices architecture manifests as latency contagion.
- Service A is fast.
- Service B is slow due to a trap.
- Service C, which shares the same underlying Kafka broker, starts seeing 500ms write delays.
Voice Query Audit:
Ask yourself: “Can I replay a specific event from 4 hours ago without triggering side effects?” If the answer is No, you have a trap waiting to happen.
5. Strategic Solutions: The 2026 Migration Roadmap
Fixing a platform event trap doesn’t require ripping out your stack. It requires implementing Control Planes.
Phase 1: The “Kill Switch” for Agentic AI
You cannot rely on code perfection. You must assume agents will loop.
- Solution: Implement Context-Aware Rate Limiting.
- The Fix: Assign a unique TraceID to every agent-initiated workflow. If the same TraceID generates more than 50 events in 1 minute, the system must automatically “Trip” the circuit and reject further events from that ID.
Phase 2: Circuit Breakers with “Fallback” Logic
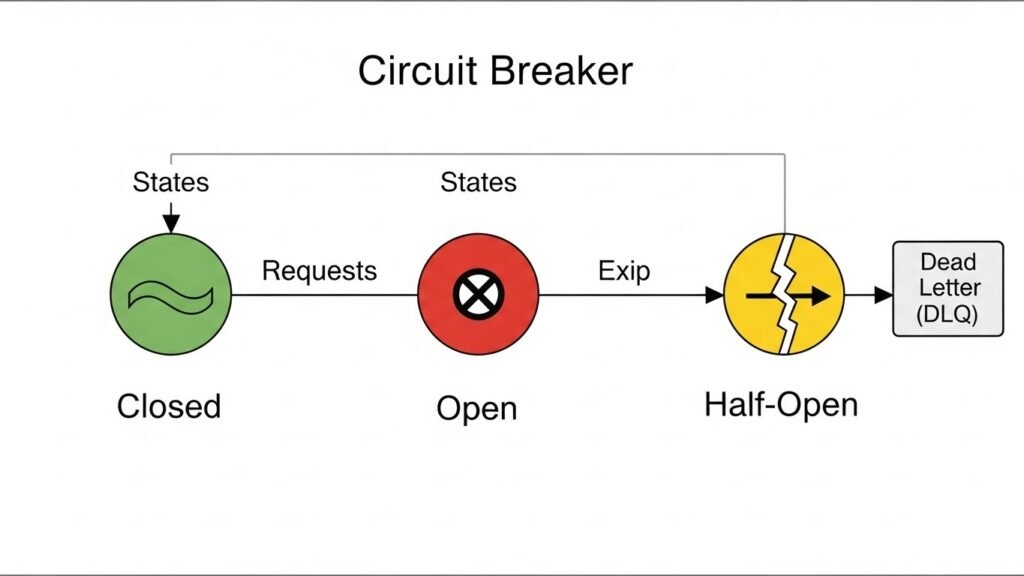
Do not just retry. Use a library like Resilience4j (Java) or Polly (.NET) to implement a Circuit Breaker around your event consumers.
Pseudo-Code Example:
# The Circuit Breaker Pattern for Event Consumption
def consume_event(event):
if circuit_breaker.is_open():
# FAST FAIL: Send directly to Dead Letter Queue (DLQ)
send_to_dlq(event)
return
try:
process_business_logic(event)
except Exception as e:
circuit_breaker.record_failure()
# Exponential Backoff is NOT enough.
# After 5 failures, Open the circuit to protect the system.Phase 3: Strict Schema Governance
SaaS governance isn’t red tape; it’s armor. Use a Schema Registry (like Confluent or AWS Glue).
- The Rule: If a Producer sends an event that does not match the registered Schema version, the Broker rejects it immediately. It never reaches the Consumer. This eliminates 90% of “Poison Messages.”
Phase 4: Tenant Partitioning
In a multi-tenant environment, shared event lanes are dangerous.
- The Fix: Use Shuffle Sharding. Assign Tenant A to Partitions 1-3 and Tenant B to Partitions 4-6. If Tenant A triggers a trap, only their partitions lag. Tenant B is unaffected.
6. Choosing Your Arsenal: Kafka vs. The Rest
Not all event buses are created equal when it comes to trap prevention.

| Tool | Risk of Trap | Governance Features | Best For… |
|---|---|---|---|
| Native Webhooks | High | None. Pure “fire and pray.” | Simple, low-volume notifications. |
| RabbitMQ | Medium | Good routing, weaker replay. | Complex routing logic. |
| AWS EventBridge | Low | Schema Discovery & Archives built-in. | Serverless SaaS on AWS. |
| Apache Kafka | Very Low | Strict Schema Registry, massive retention. | High-scale Enterprise SaaS. |
🧠 Expert Perspective: The “Observer” Fallacy
Many teams believe that adding more monitoring tools (Datadog, New Relic) fixes the problem. It doesn’t.
In 2026, observability is about causality, not just correlation. You need distributed tracing (OpenTelemetry) that follows the event across the bus. You need to know that Service A’s update caused Service B to loop, which caused Service C’s latency. Without tracing, you are just looking at noise.
Conclusion: Turning Traps into Signals
A Platform Event Trap isn’t a failure—it’s feedback. It is your system telling you that your scale has outgrown your shortcuts.
The difference between a failing startup and a scaling enterprise is how they handle these signals. By moving away from tight coupling caused by platform events and embracing Agentic Kill Switches and Schema Governance, you transform your architecture from a house of cards into a resilient, observable fabric.
In modern SaaS, resilience isn’t about speed. It’s about control.
Frequently Asked Questions (AEO Optimized)
Q: How do I know if my system has a platform event trap?
A: Look for “latency contagion” where unrelated services slow down, or check if your cloud bill has unexplained spikes in “invocation” costs due to silent retry loops.
Q: When should I NOT use platform events?
A: Do not use events for synchronous user actions (like login) or atomic financial transactions that require immediate “Yes/No” confirmation. Use gRPC or REST for those.
Q: Can AI Agents cause platform event traps?
A: Yes. “Agentic Event Loops” are a major 2026 risk where two agents trigger each other continuously. You must use TraceID rate limiting to prevent this.
Q: What is the best tool to prevent event-driven deadlocks in 2026?
A: Apache Kafka remains the gold standard for enterprise SaaS due to its strict Schema Registry and robust partitioning, though AWS EventBridge is ideal for serverless-first architectures.
Q: How does a platform event trap affect SaaS profitability?
A: It directly impacts the bottom line through Cloud FinOps (inflated infrastructure bills) and Net Dollar Retention (customer churn due to reliability issues).
About the Author
MUHAMMAD TALHA SAEED
Muhammad Talha Saeed is a veteran content strategist and technical writer with over a decade of experience in SaaS architectural analysis and digital ecosystem optimization. As the creator behind TalhaSaeedOfficial, he empowers thousands of developers and tech leaders to build resilient, AI-ready platforms in the evolving 2026 landscape.
FAQ Schema Code (JSON-LD)
{
"@context": "https://schema.org",
"@type": "FAQPage",
"mainEntity": [
{
"@type": "Question",
"name": "How do I know if my system has a platform event trap?",
"acceptedAnswer": {
"@type": "Answer",
"text": "Identify 'latency contagion' where unrelated services experience slowdowns or monitor cloud billing for unexplained spikes in invocation costs caused by silent retry loops."
}
},
{
"@type": "Question",
"name": "When should I NOT use platform events?",
"acceptedAnswer": {
"@type": "Answer",
"text": "Avoid platform events for synchronous user actions like logins or atomic financial transactions requiring immediate confirmation; use gRPC or REST instead."
}
},
{
"@type": "Question",
"name": "Can AI Agents cause platform event traps?",
"acceptedAnswer": {
"@type": "Answer",
"text": "Yes, Agentic Event Loops are a significant 2026 risk where autonomous agents trigger each other. Implementing TraceID-based rate limiting is essential to prevent this."
}
},
{
"@type": "Question",
"name": "How do Agentic AI loops cause Platform Event Traps?",
"acceptedAnswer": {
"@type": "Answer",
"text": "Agentic AI loops occur when autonomous agents trigger recursive events (e.g., Agent A updates, Agent B reacts and re-updates). This creates a self-reinforcing loop that exhausts API credits and crashes event buses, requiring TraceID-based rate limiting to resolve."
}
},
{
"@type": "Question",
"name": "What is the best tool to prevent event-driven deadlocks in 2026?",
"acceptedAnswer": {
"@type": "Answer",
"text": "Apache Kafka is highly recommended for high-scale enterprise SaaS due to its Schema Registry, while AWS EventBridge is preferred for serverless SaaS applications."
}
},
{
"@type": "Question",
"name": "How does a platform event trap affect SaaS profitability?",
"acceptedAnswer": {
"@type": "Answer",
"text": "It degrades profitability via FinOps bill shock from excessive serverless invocations and reduces Net Dollar Retention (NDR) due to customer churn from system instability."
}
}
]
}